Journal list menu

The sharing of data will enable researchers to do better science. Open science advocates for access to high-quality shared data, reproducibility, the provision of negative as well as positive results, and clear licensing that describes how data may be used. Improvements in technical infrastructure and software have the potential to make collaboration more effective, ultimately accelerating science and making it more impactful. However, the advances in areas like machine learning and artificial intelligence can only be fully exploited if researchers have access to the high-quality data that the scientific community generates. (Based on Matthew Todd’s statement on The Importance of Open Science at Chemistry Europe)
Committed to promote open access and open data, Chemistry Europe presents this Special Collection that compiles a selection of works on these topics, published across our portfolio. A recording to the Virtual Symposium organized by ChemistryOpen, "Open Data and Open-Source Research", is also available.
NOTE: This Special Collection consists of non-commissioned content published by journals across the Chemistry Europe portfolio and chosen for inclusion by those journals’ editors. All content included in this Special Collection has been subjected to full standard peer review handled solely by the journals’ in-house editorial teams. For further details, please refer to our Notice to Authors.
Export Citations
Cover Pictures
Front Cover: A Unified Research Data Infrastructure for Catalysis Research – Challenges and Concepts (ChemCatChem 14/2021)
- First Published: 05 July 2021

The Front Cover illustrates the dynamics and complexity of catalysis. Handling data in catalysis research in a sharable and re-usable way is an unsolved challenge. A concept is proposed by the initiative NFDI4Cat, a consortium in the German NFDI (National Research Data Infrastructure), that serves all aspects of catalysis research. Indicated in the picture is a vision of integrating all research data along the catalysis value chain, from molecule to chemical process. In their Concept, C. Wulf et al. discuss core topics and challenges. More information can be found in the Concept by C. Wulf et al.
Front Cover: What Can Text Mining Tell Us About Lithium-Ion Battery Researchers’ Habits? (Batteries & Supercaps 5/2021)
- First Published: 21 April 2021

The Front Cover illustrates an ideal scientific literature, in which all the data are systematically disclosed and available for researchers, together with artificial intelligence algorithms aiming to bring new light on the next generation of batteries. More information can be found in the Concept by A. A. Franco and co-workers.
Articles
How Research Data Management Plans Can Help in Harmonizing Open Science and Approaches in the Digital Economy
- First Published: 29 December 2022
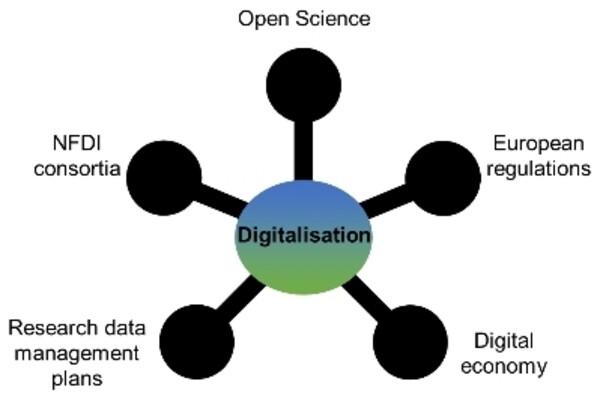
The integration of open science into a digital economy, while considering legal European regulations, is a balancing act. Here research data management plans play a key role and has the potential to combine the interests of researchers as data producers and the public as data users in publicly funded projects.
Data Management Plans: the Importance of Data Management in the BIG-MAP Project
- First Published: 28 August 2021
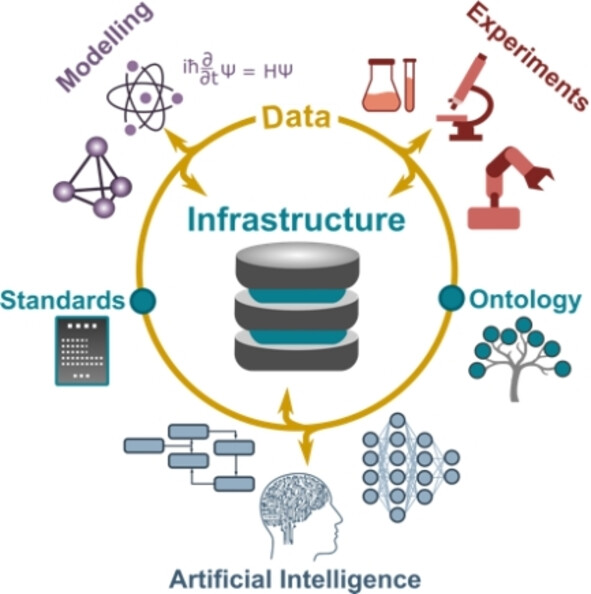
FAIR play: Standardization and ontology have the role of homogenizing the data and make them interoperable. Data Management Plans are increasingly important for accelerating research. Here, we describe the case of BIG-MAP, a cross-disciplinary project targeting disruptive battery-material discoveries. Central in the project is the role of data and its infrastructure to store and exchange research data. Standards and an ontology further ensures data that can be interoperated across different domains, from theory to experiments and artificial intelligence.
Standardized Data, Scalable Documentation, Sustainable Storage – EnzymeML As A Basis For FAIR Data Management In Biocatalysis
- First Published: 17 July 2021

Reproducibility crisis solution: An infrastructure is proposed based on EnzymeML, a novel standardized data exchange format, which enables reporting, exchange, and storage of enzymatic data according to the FAIR data principles. EnzymeML facilitates the application of the STRENDA Guidelines and thus makes data on enzyme-catalyzed reactions findable, accessible, interoperable, and reusable. EnzymeML enables the comprehensive documentation of metadata, thus fostering reproducibility and replicability in enzymology and biocatalysis.
Ragone Plots for Electrochemical Double-Layer Capacitors
- First Published: 17 May 2021

A guide to Ragone plots: This manuscript presents a step-by-step procedure to provide a correct Ragone plot (RP). Also, simple theoretical demonstrations of how to get each fundamental equation are presented. In general, this work contributes as a guide to obtain reliable RPs for electrochemical double-layer capacitors.
The Repository Chemotion: Infrastructure for Sustainable Research in Chemistry
- First Published: 12 August 2020
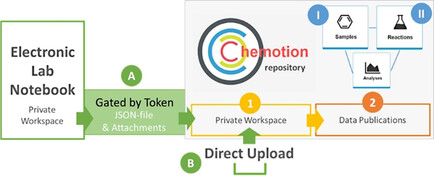
The repository Chemotion provides solutions for current challenges to store research data in a feasible manner. A main advantage of Chemotion is the comprehensive functionality, offering options to collect, prepare, and reuse data with discipline-specific methods and data-processing tools.
A Unified Research Data Infrastructure for Catalysis Research – Challenges and Concepts
- First Published: 10 March 2021

Data Sharing: The German NFDI initiative (National Research Data Infrastructure) aims to create a unique research data infrastructure covering all scientific disciplines. One of the firstly funded consortia, NFDI4Cat (NFDI for Catalysis-related Sciences), proposes a concept that serves all aspects and fields of catalysis research.
What Can Text Mining Tell Us About Lithium-Ion Battery Researchers’ Habits?
- First Published: 29 January 2021

Breaking the status quo: An in-house text mining algorithm is used here to study the Na- and Li-ion battery researchers’ habits in terms of how often certain key electrode and cell features are reported and about the scattered ways in which they are reported in scientific literature. Our results clearly show a systematic lack of certain key data, calling for standardization actions.
Chemotion Repository, a Curated Repository for Reaction Information and Analytical Data
- First Published: 17 September 2020
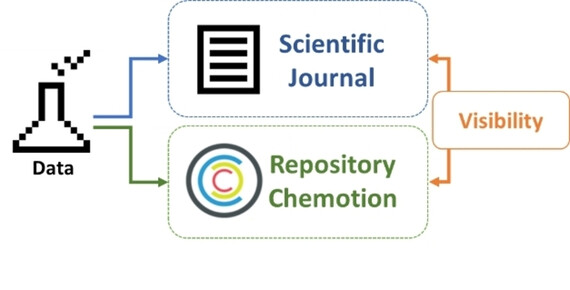
The domain specific repository Chemotion preserves research data of chemical syntheses and analytical measurements such as chromatography or spectroscopy data. The repository provides these data for other scientists to foster their re-use and to allow a fast reproduction of published work. Several automated mechanisms to check the plausibility of the data and a curation workflow support scientists in their effort to provide data of high quality.
Open Data in Catalysis: From Today's Big Picture to the Future of Small Data
- First Published: 23 October 2020
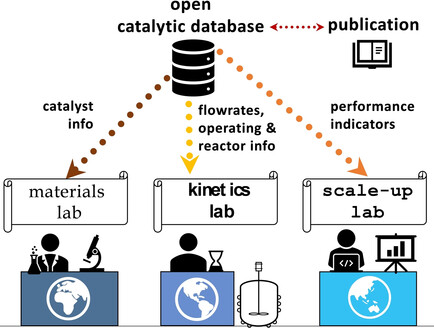
Catalysis informatics: Sharing data enables scientists to join efforts worldwide to solve key scientific puzzles. For optimal data (re)usage, raw data should be shared in machine readable unified formats via open databases. Specific guidelines for data sharing in catalysis are discussed, together with relevant tools for data-centric knowledge generation.
Six Laws of Open Source Drug Discovery
- First Published: 15 October 2019

Six to swear by! Society needs effective and affordable medicines. We currently have at our disposal essentially one system to discover and develop drugs, and there are many areas where this system struggles to deliver, for example to combat antimicrobial resistance, or tropical diseases, or dementia. It is sensible to cultivate alternative, competing approaches to drug discovery and development. A genuinely new alternative is to open up the entire research cycle, abandoning secrecy altogether. This “open source” approach has now been trialed and the lessons learned distilled to six laws of operation that help to clarify working practices. This article examines and explains those laws, which can be adopted by anyone wishing to create medicines using an inclusive, public process.
Caveat Usor: Assessing Differences between Major Chemistry Databases
- First Published: 16 February 2018
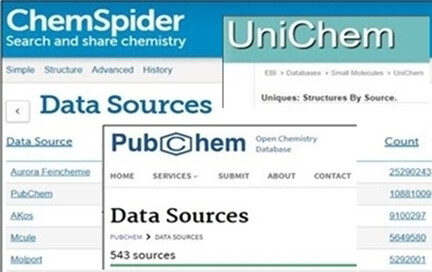
The three databases of PubChem, ChemSpider, and UniChem capture the majority of open chemical structure records. Collectively, they constitute a massively enabling resource for cheminformatics, chemical biology, and drug discovery. It is important for users to have at least some appreciation of differential content to enable utility judgments for the tasks at hand. This turns out to be challenging. By comparing the three resources in detail, this review assesses their differences, some of which are not obvious.